生成式AI驅(qū)動的模型規(guī)模與複雜度急遽上升,正迫使晶片架構(gòu)以遠(yuǎn)超摩爾定律的速度進(jìn)化。在這場硬體競賽中,NVIDIA、AMD、Google等科技巨頭紛紛推出「算力核彈級」晶片,並在效能、功耗與生態(tài)系三大戰(zhàn)場上展開正面交鋒。
2023年,ChatGPT在短短五天內(nèi)突破億級用戶,徹底改寫科技與應(yīng)用場景的版圖。背後支撐其運(yùn)行的GPT-4模型,不僅需動用約1.7萬顆GPU,耗電量更高達(dá)50GWh,相當(dāng)於3.6萬戶家庭全年的用電需求。而最新的Sora影片生成模型,其單次訓(xùn)練成本更被傳已突破5億美元,堪稱「算力黑洞」的代表。

| 圖一 : ChatGPT需耗用大量的GPU運(yùn)算資源。 |
|
生成式AI驅(qū)動的模型規(guī)模與複雜度急遽上升,正迫使晶片架構(gòu)以遠(yuǎn)超摩爾定律的速度進(jìn)化。在這場硬體競賽中,NVIDIA、AMD、Google等科技巨頭紛紛推出「算力核彈級」晶片,並在效能、功耗與生態(tài)系三大戰(zhàn)場上展開正面交鋒。OpenAI執(zhí)行長Sam Altman更喊出募資7兆美元自建晶片廠,預(yù)示這場競賽不僅將改寫AI產(chǎn)業(yè)的格局,更可能重塑整個半導(dǎo)體生態(tài)。
AI模型推動硬體需求徹底重構(gòu)
從GPT-3的1,750億參數(shù)到GPT-4的1.8兆參數(shù),參數(shù)量膨脹超過10倍,模型訓(xùn)練所需的算力也呈指數(shù)級上升。而最新的多模態(tài)模型,如OpenAI的Sora,更需同時處理文本、影像與物理模擬,Transformer架構(gòu)中的「注意力機(jī)制」(Attention)大幅推升記憶體頻寬需求,是純語言模型的3倍以上。
另一方面,即時生成需求也正在向邊緣裝置逼近。例如Stable Diffusion要求裝置能在1秒內(nèi)生成一張512×512解析度的圖片,這推動NPU(神經(jīng)網(wǎng)路處理單元)導(dǎo)入如動態(tài)電壓與頻率調(diào)整(DVFS)等技術(shù)來平衡性能與功耗。
三大技術(shù)關(guān)鍵指標(biāo)浮現(xiàn)
為因應(yīng)模型規(guī)模與即時需求並存的挑戰(zhàn),三大硬體升級重點(diǎn)成為焦點(diǎn):
? 記憶體頻寬:HBM3e(高頻寬記憶體)堆疊技術(shù)進(jìn)一步解放資料吞吐瓶頸。
? 稀疏計(jì)算支援:Google TPU v6強(qiáng)化稀疏矩陣運(yùn)算能力,大幅提升訓(xùn)練效率。
? 高速互連:AMD MI300X採用第三代Infinity Fabric技術(shù),將CPU與GPU間延遲壓縮至35ns,強(qiáng)化即時推理場景的反應(yīng)速度。
三大巨頭硬體技術(shù)的競速戰(zhàn)
NVIDIA:CUDA帝國下的霸權(quán)延伸
作為AI晶片市場的霸主,NVIDIA以CUDA軟體平臺建立起無可撼動的技術(shù)護(hù)城河。其最新架構(gòu)在大型語言模型訓(xùn)練上表現(xiàn)卓越,加上CUDA 12支援動態(tài)並行運(yùn)算,使開發(fā)者能更靈活配置資源,提升訓(xùn)練效率。
目前NVIDIA已獨(dú)佔(zhàn)全球92%的AI訓(xùn)練市場,儘管單顆高階AI晶片售價高昂,卻反而催生出如CoreWeave等GPU雲(yún)端租賃服務(wù),讓中小企業(yè)得以接觸尖端算力。
NVIDIA之所以能在生成式AI浪潮中脫穎而出,關(guān)鍵在於其GPU架構(gòu)針對深度學(xué)習(xí)工作負(fù)載進(jìn)行高度優(yōu)化。以H100為例,其內(nèi)建的Tensor Core第四代張量處理器專為矩陣運(yùn)算設(shè)計(jì),支援FP8、BF16等混合精度格式,讓大型語言模型訓(xùn)練速度提升至前代的2倍以上,同時保持精度不墜。
此外,NVIDIA也針對大模型運(yùn)行瓶頸進(jìn)行記憶體創(chuàng)新,H100搭載的HBM3記憶體頻寬高達(dá)3 TB/s,遠(yuǎn)高於傳統(tǒng)GDDR6,顯著降低模型參數(shù)載入與中間層數(shù)據(jù)傳遞的延遲。再搭配NVLink互連技術(shù),可將多張GPU組成高速集群,實(shí)現(xiàn)「多GPU如單GPU」的運(yùn)算體驗(yàn),滿足如GPT-4、Sora等超大模型的分散式訓(xùn)練需求。
AMD異構(gòu)運(yùn)算的逆襲
AMD的MI300X以異構(gòu)整合架構(gòu)為亮點(diǎn),將Zen 4 CPU、CDNA 3 GPU與HBM3記憶體整合為單一APU,記憶體容量高達(dá)192GB,並大幅減少資料搬移造成的瓶頸。其性價比策略也具競爭力:在同等算力下,MI300X價格比H100低30%,並支援ROCm開源軟體框架,已成功打入Meta的Llama 3訓(xùn)練系統(tǒng)。不過,相較於CUDA,其軟體生態(tài)仍有明顯落差,目前PyTorch對MI300X的運(yùn)算支援覆蓋率僅約78%。
AMD在AI晶片領(lǐng)域的突圍,建立於其長年經(jīng)營的異質(zhì)運(yùn)算(Heterogeneous Computing)技術(shù)基礎(chǔ)之上。MI300X採用APU(Accelerated Processing Unit)架構(gòu),將高效能CPU核心(Zen 4)與GPU核心(CDNA 3)以及高頻寬記憶體(HBM3)整合於同一封裝中,透過統(tǒng)一記憶體架構(gòu)(Unified Memory Architecture),讓CPU與GPU可共享高達(dá)192GB的HBM3記憶體資源,大幅降低資料搬移造成的延遲與功耗。
這種設(shè)計(jì)特別適用於生成式AI推理階段,例如在需要快速回應(yīng)的即時應(yīng)用中,資料無需在CPU與GPU間頻繁複製,讓整體運(yùn)算流程更高效、連續(xù)。此外,CDNA 3架構(gòu)內(nèi)建對稀疏運(yùn)算(Sparse Compute)與混合精度計(jì)算(例如FP8、BF16)的原生支援,進(jìn)一步提升AI模型訓(xùn)練與推理的能源效率。
AMD的架構(gòu)策略,重點(diǎn)不在於單點(diǎn)性能的極致,而是以系統(tǒng)級協(xié)同與封裝創(chuàng)新爭取效能與成本的最佳平衡,這讓MI300X在資料中心與企業(yè)AI部署中,成為一項(xiàng)極具競爭力的選擇。
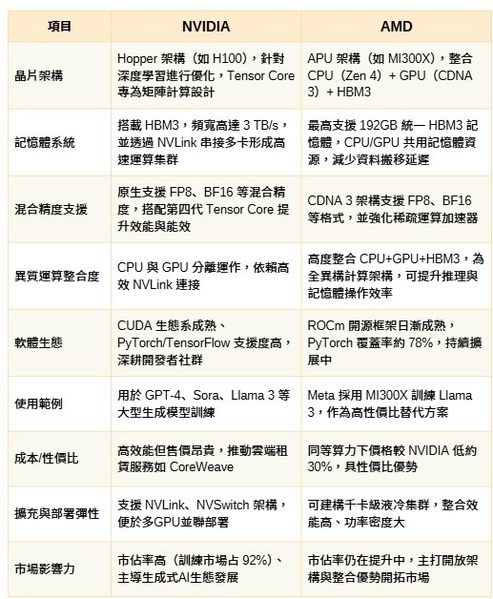
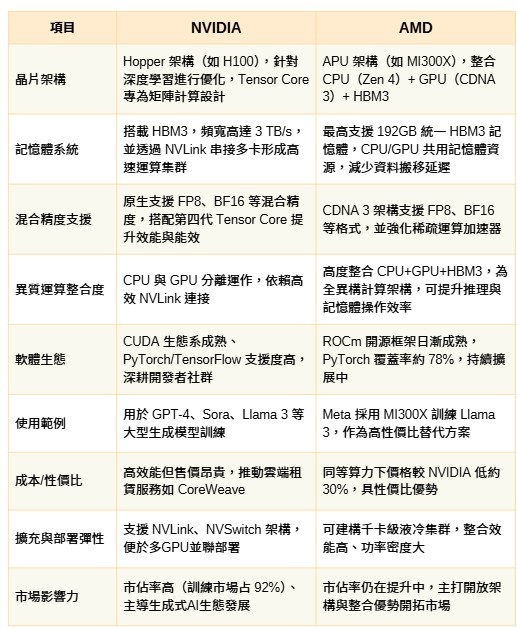
| 圖二 : NVIDIA與AMD在生成式AI應(yīng)用領(lǐng)域中的運(yùn)算優(yōu)勢比較。 |
|
Google封閉但高效的垂直整合
Google以TPU v6為核心推出的Hypercomputer平臺,是垂直整合的極致範(fàn)例,強(qiáng)調(diào)能效與協(xié)同運(yùn)作。透過優(yōu)化的硬體設(shè)計(jì)與軟體疊代,其整體運(yùn)行效率領(lǐng)先業(yè)界。
然而,這套系統(tǒng)僅供Google Cloud內(nèi)部與合作客戶使用,其封閉性成為限制其普及化的最大障礙。
算力的突破口
Meta的Llama 3與開源模式
Meta的Llama 3展示了開源模型在算力資源緊張情境下的可行性。訓(xùn)練一個參數(shù)量為700億的模型,需動用7,200顆H100運(yùn)行90天,光電費(fèi)就高達(dá)870萬美元,相當(dāng)於3,000臺特斯拉Model Y的售價。
為解決這一痛點(diǎn),Meta導(dǎo)入PyTorch Fully Sharded Data Parallel(FSDP)技術(shù),能將模型參數(shù)分散至512張GPU上,大幅提升訓(xùn)練效率達(dá)70%。
CoreWeave雲(yún)端算力
CoreWeave則以「算力即服務(wù)」模式出線,提供GPU分鐘級租賃服務(wù),H100實(shí)例每小時費(fèi)用僅6.5美元。其與NVIDIA合作開發(fā)的液冷伺服器叢集,功率密度達(dá)傳統(tǒng)資料中心的8倍,支援千卡級高並行運(yùn)算,成為中小型AI開發(fā)者重要算力來源。
不過,其商業(yè)模式也受到外部市場影響。例如過去以太坊合併,從工作量證明 (PoW) 轉(zhuǎn)為持有量證明(PoS)後,GPU需求暴跌曾導(dǎo)致租金價格瞬間下修47%,揭示出其潛在風(fēng)險。
下一世代xPU技術(shù)的戰(zhàn)場
量子與光子:顛覆既有邏輯的潛力選項(xiàng)
IBM的量子優(yōu)勢實(shí)驗(yàn)展示出量子運(yùn)算處理特定優(yōu)化問題的潛力,速度比GPU快1,000倍,儘管目前錯誤率仍高,但前景令人矚目。
另一方面,新創(chuàng)公司Lightmatter的光子AI晶片利用光取代電子進(jìn)行傳輸與運(yùn)算,在矩陣乘法任務(wù)中能節(jié)省90%能源消耗,已獲Google Ventures等風(fēng)投資助。
OpenAI重塑晶片設(shè)計(jì)鏈
Sam Altman高喊7兆美元自建晶片廠的構(gòu)想,若以每片晶圓產(chǎn)出50顆AI晶片估算,足可建造1,750座晶圓廠,超越臺積電、三星與英特爾的總和。
此舉的戰(zhàn)略意涵明確:擺脫對NVIDIA的高度依賴,走蘋果M系列自研晶片的路線,實(shí)現(xiàn)演算法與硬體垂直整合。不過,半導(dǎo)體業(yè)界普遍質(zhì)疑其可行性,尤其在先進(jìn)製程與ASIC設(shè)計(jì)人才極度稀缺的當(dāng)下,該計(jì)畫恐淪為「資本黑洞」。
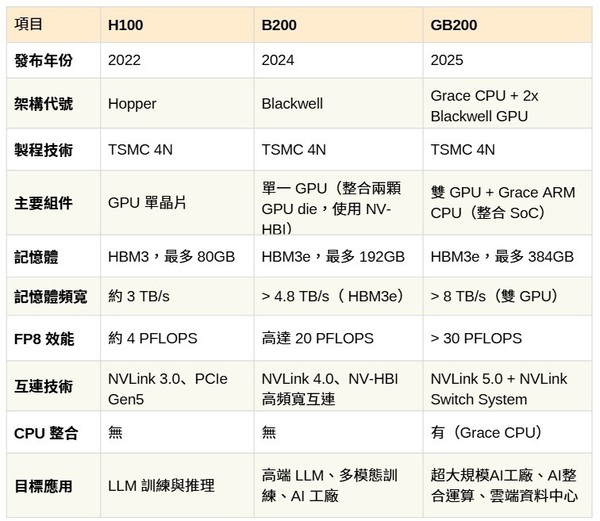
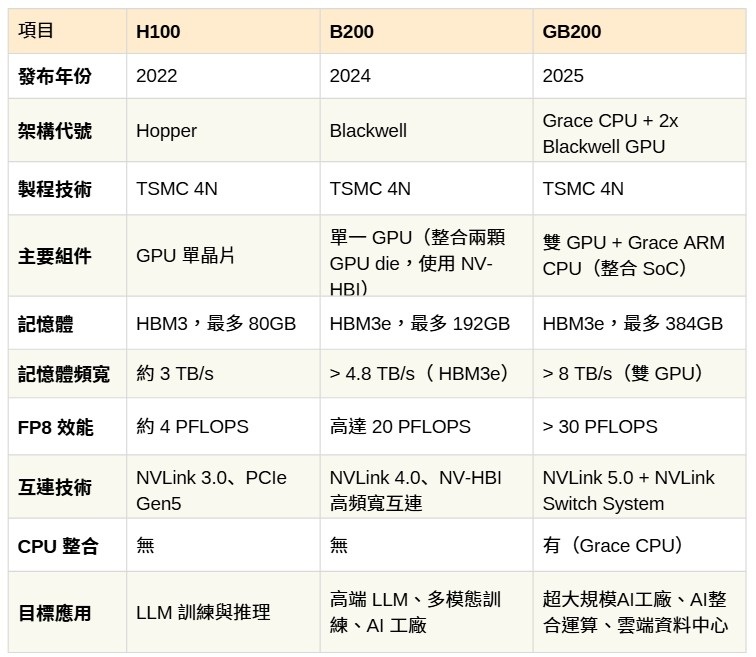
| 圖三 : NVIDIA高階AI晶片規(guī)格與應(yīng)用比較 |
|
結(jié)語
生成式AI正在從科技突破走向大規(guī)模應(yīng)用,而算力需求已成決定競爭力的關(guān)鍵要素。當(dāng)前這場硬體競賽,不再僅是晶片效能的比拼,更是生態(tài)系的全面戰(zhàn)爭。NVIDIA以CUDA鎖定開發(fā)者心智,Google透過雲(yún)端垂直整合降低總體運(yùn)算成本,AMD則以異構(gòu)架構(gòu)與性價比撬動市場。
然而,OpenAI晶片自研計(jì)畫、Meta的開源計(jì)算技術(shù),以及RISC-V的潛在顛覆,都預(yù)示這場戰(zhàn)爭沒有絕對的贏家。在AI時代,誰能在每瓦電力中萃取出最多智慧,誰就將成為新世代科技霸權(quán)的締造者。